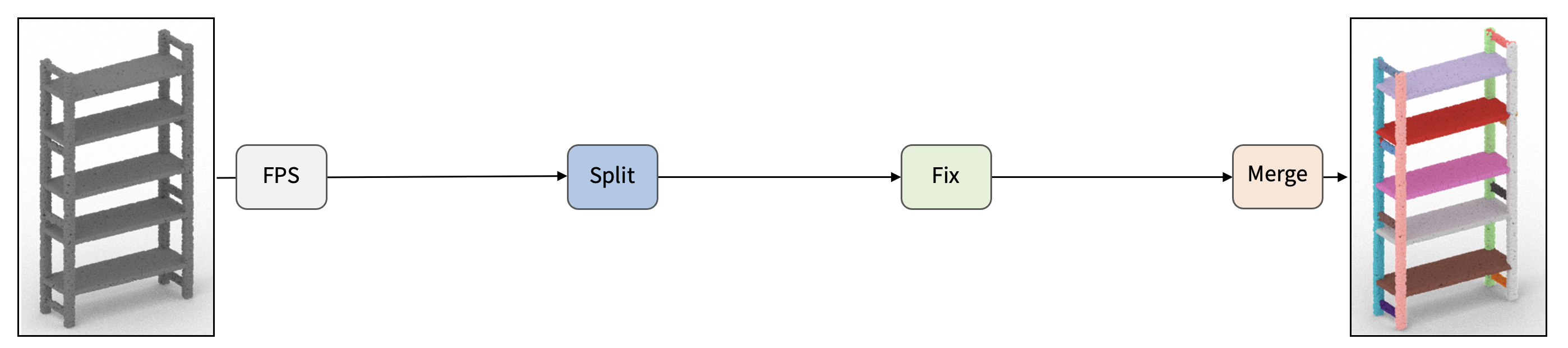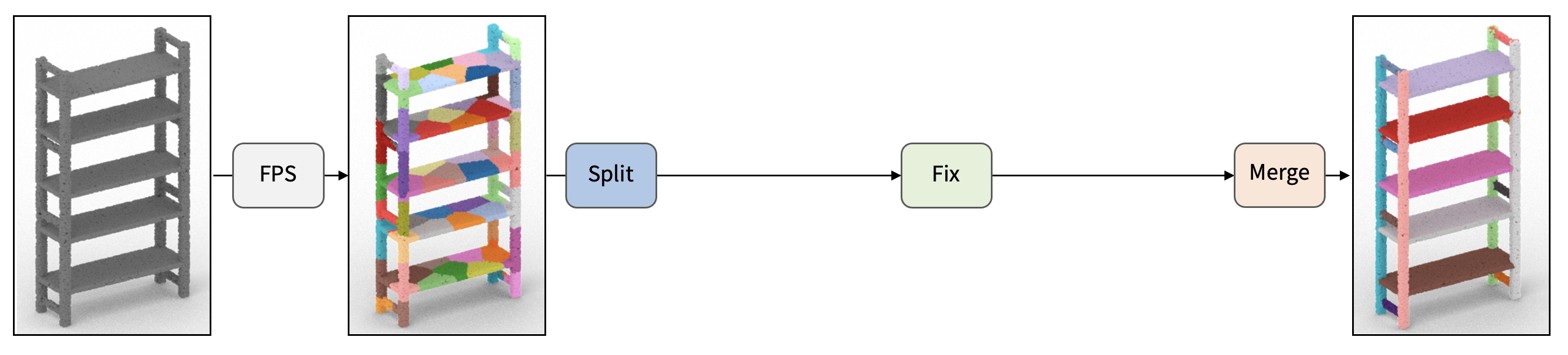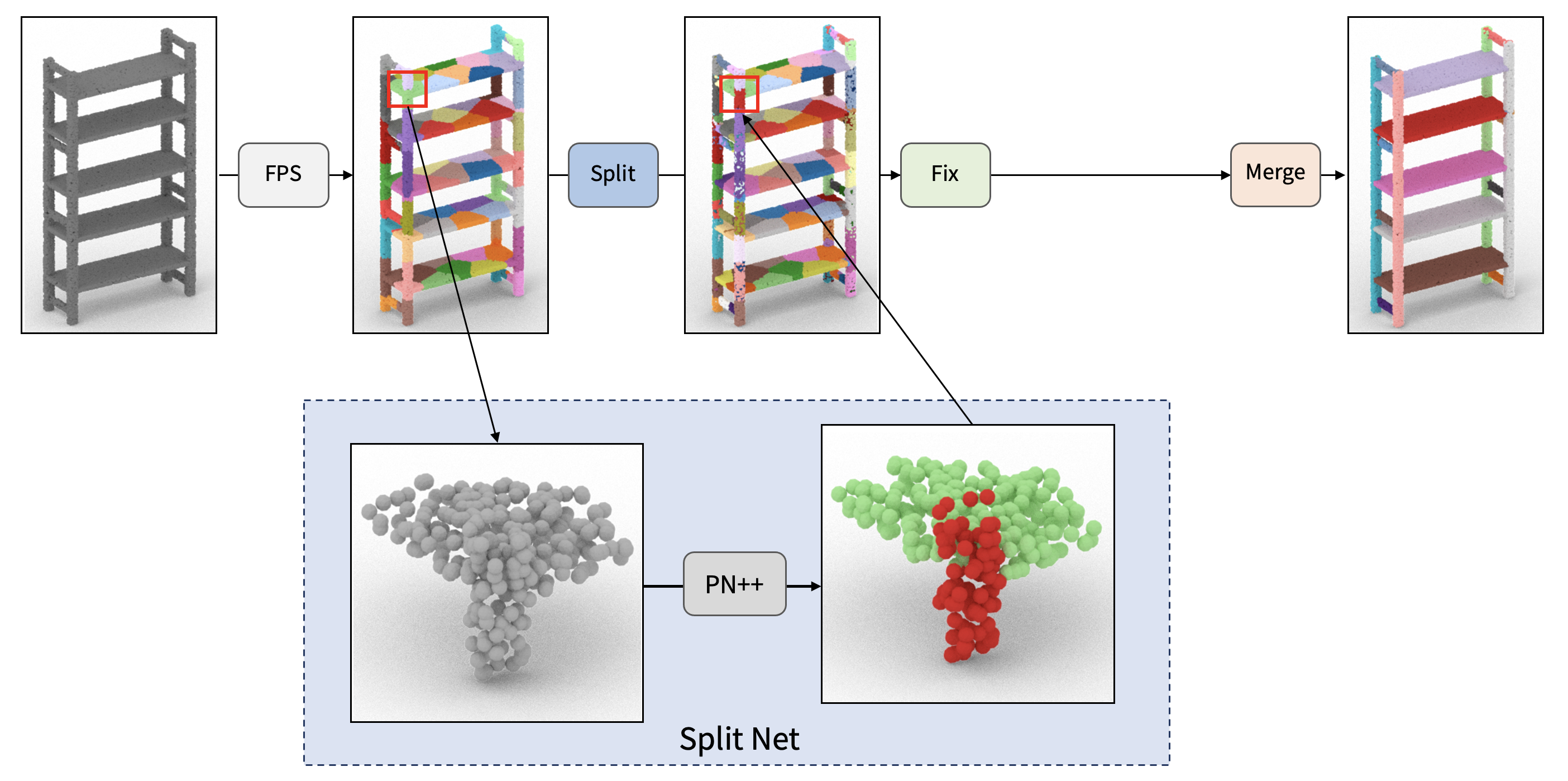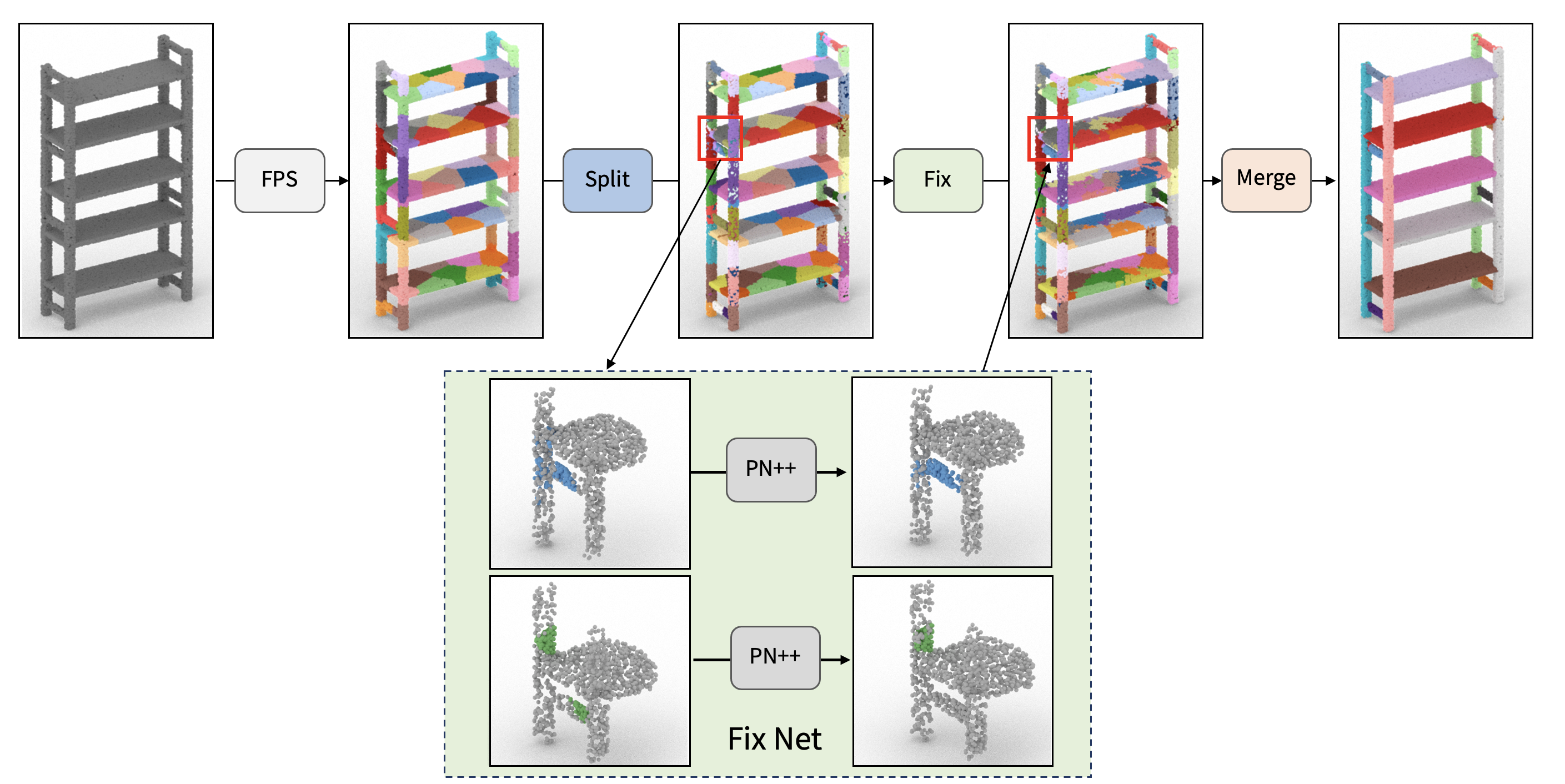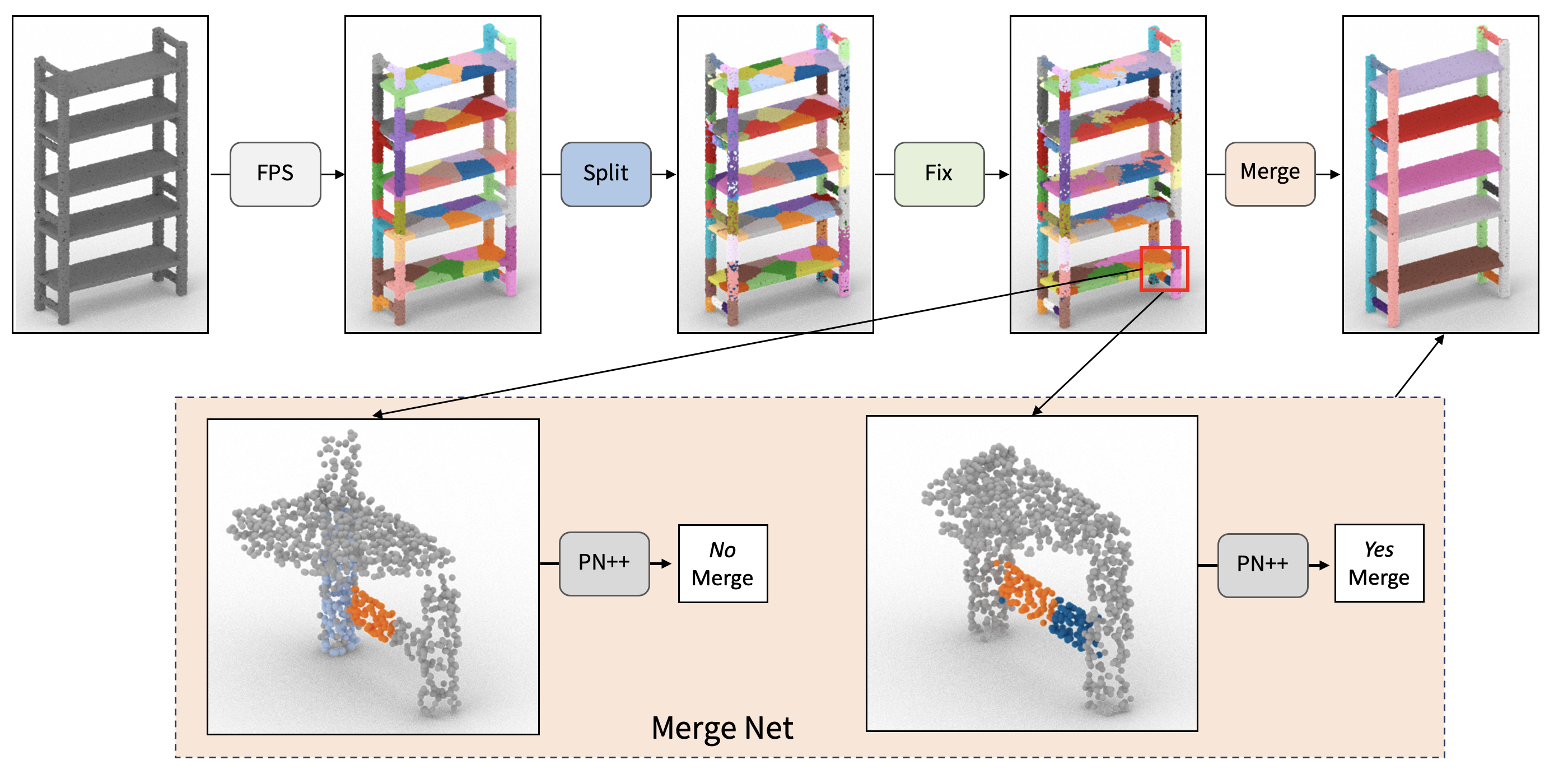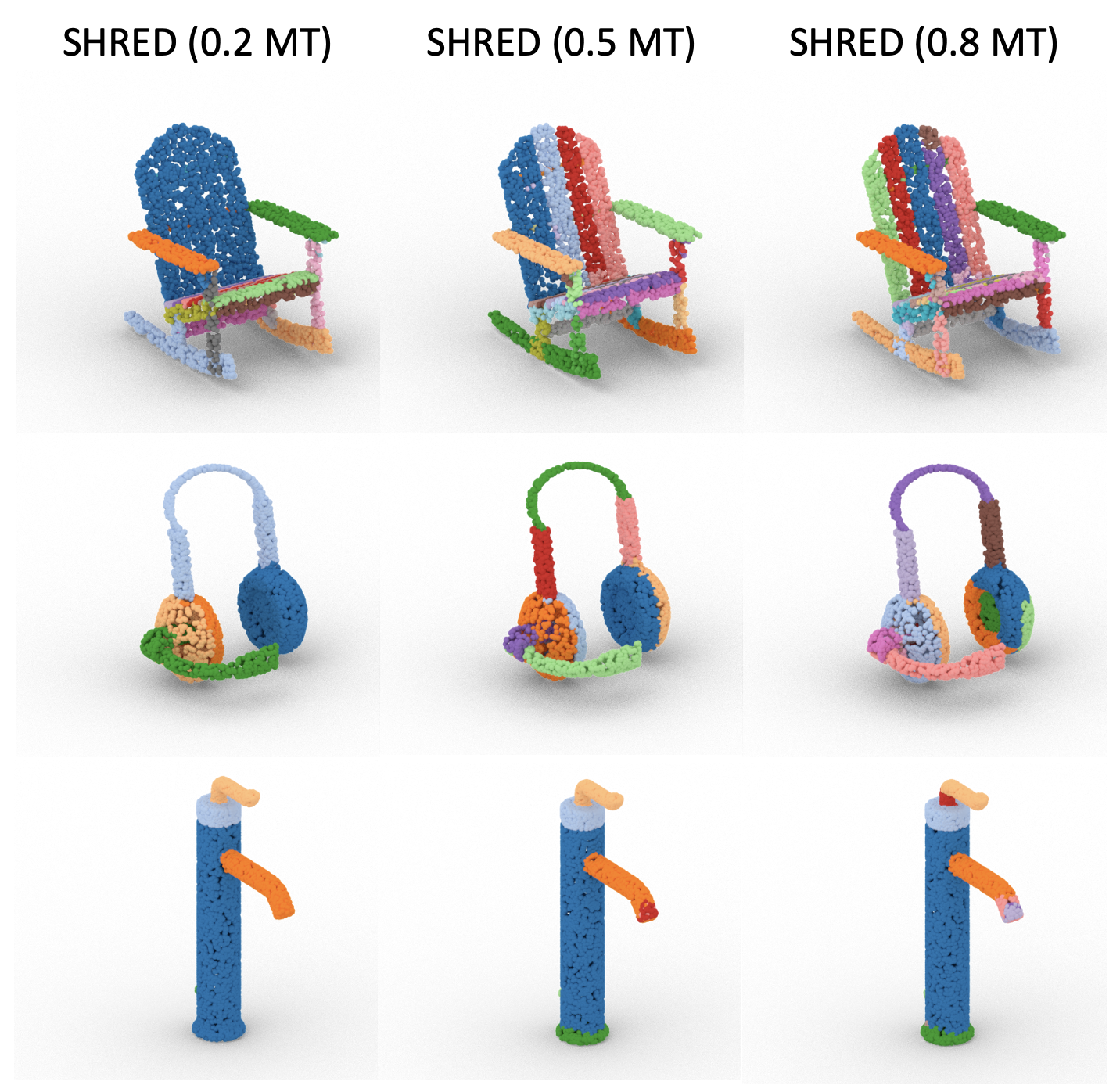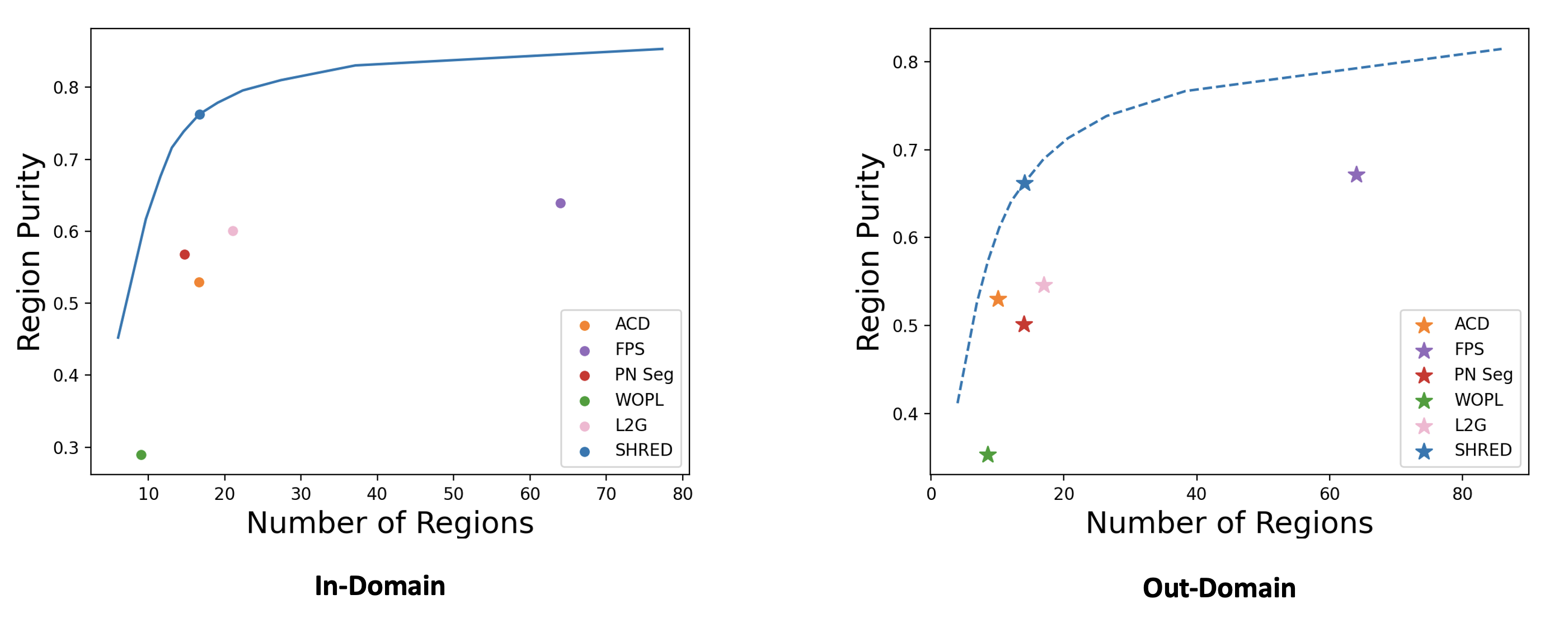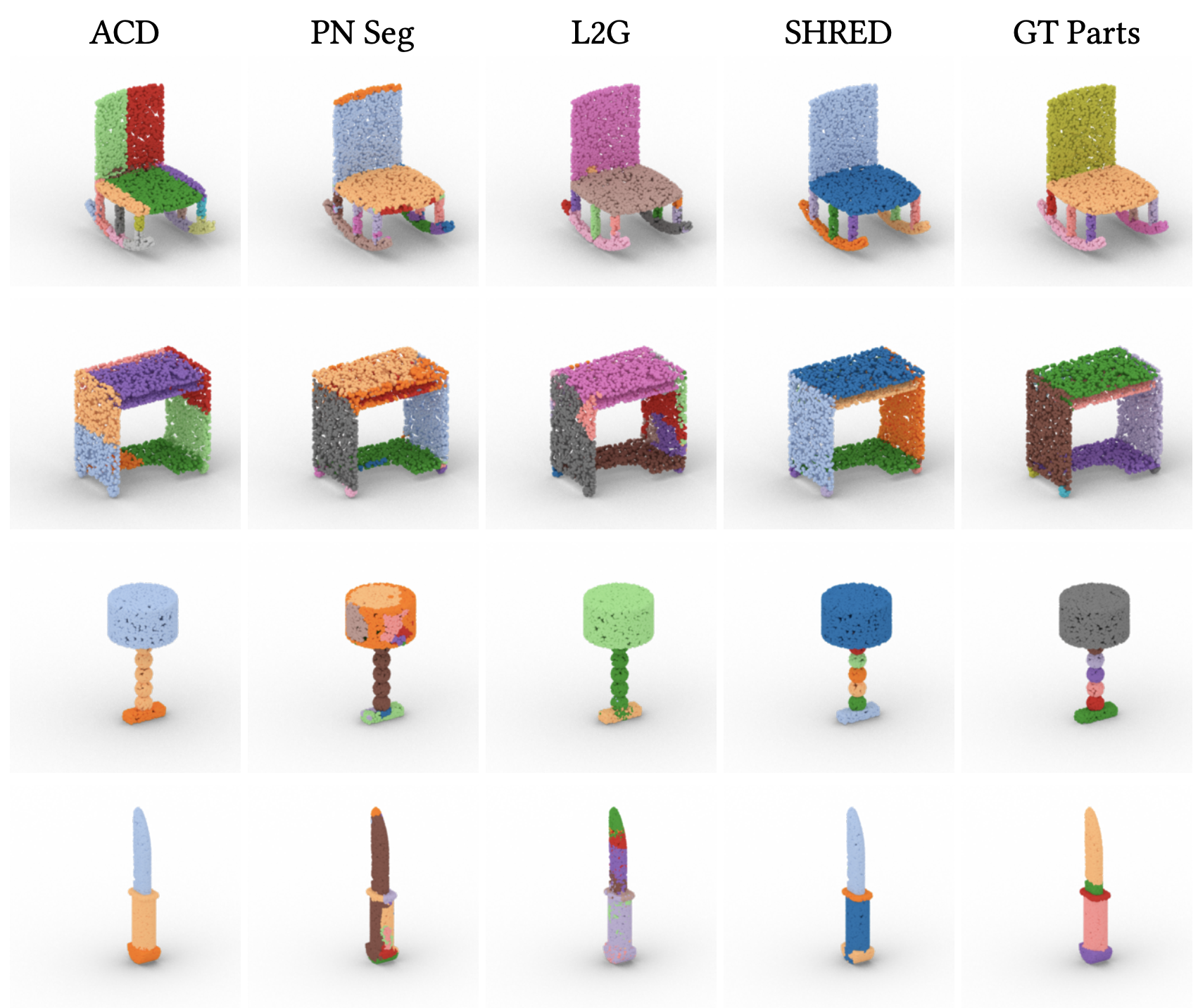
| R. Kenny Jones Aalia Habib Daniel Ritchie |
| Brown University |
@article{jones2022SHRED,
title={SHRED: 3D Shape Region Decomposition with Learned Local Operations},
author={Jones, R. Kenny and Habib, Aalia and Ritchie, Daniel},
journal={ACM Transactions on Graphics (TOG)},
volume={41},
number={6},
year={2022},
publisher={ACM},
address = {New York, NY, USA},
articleno = {186}
}