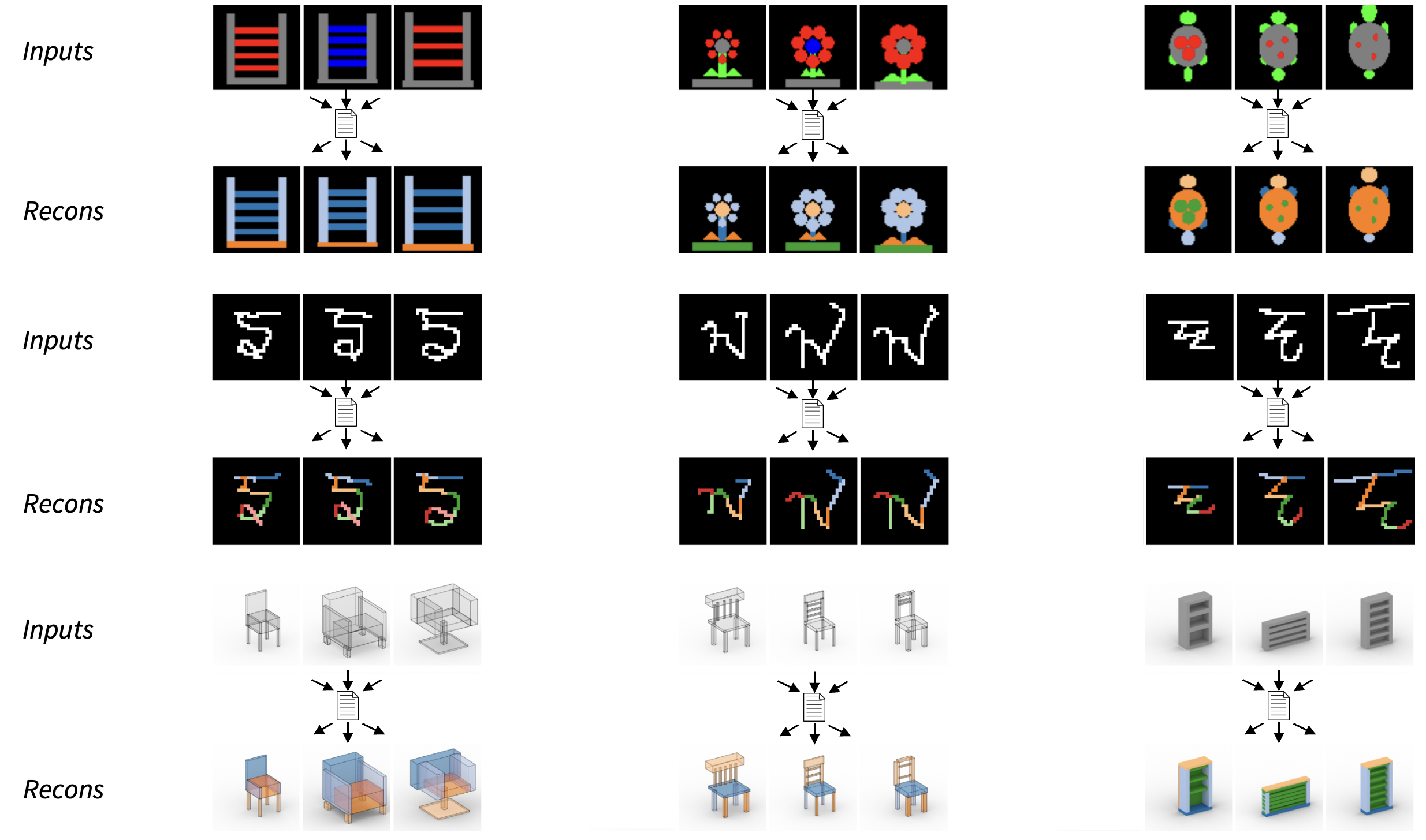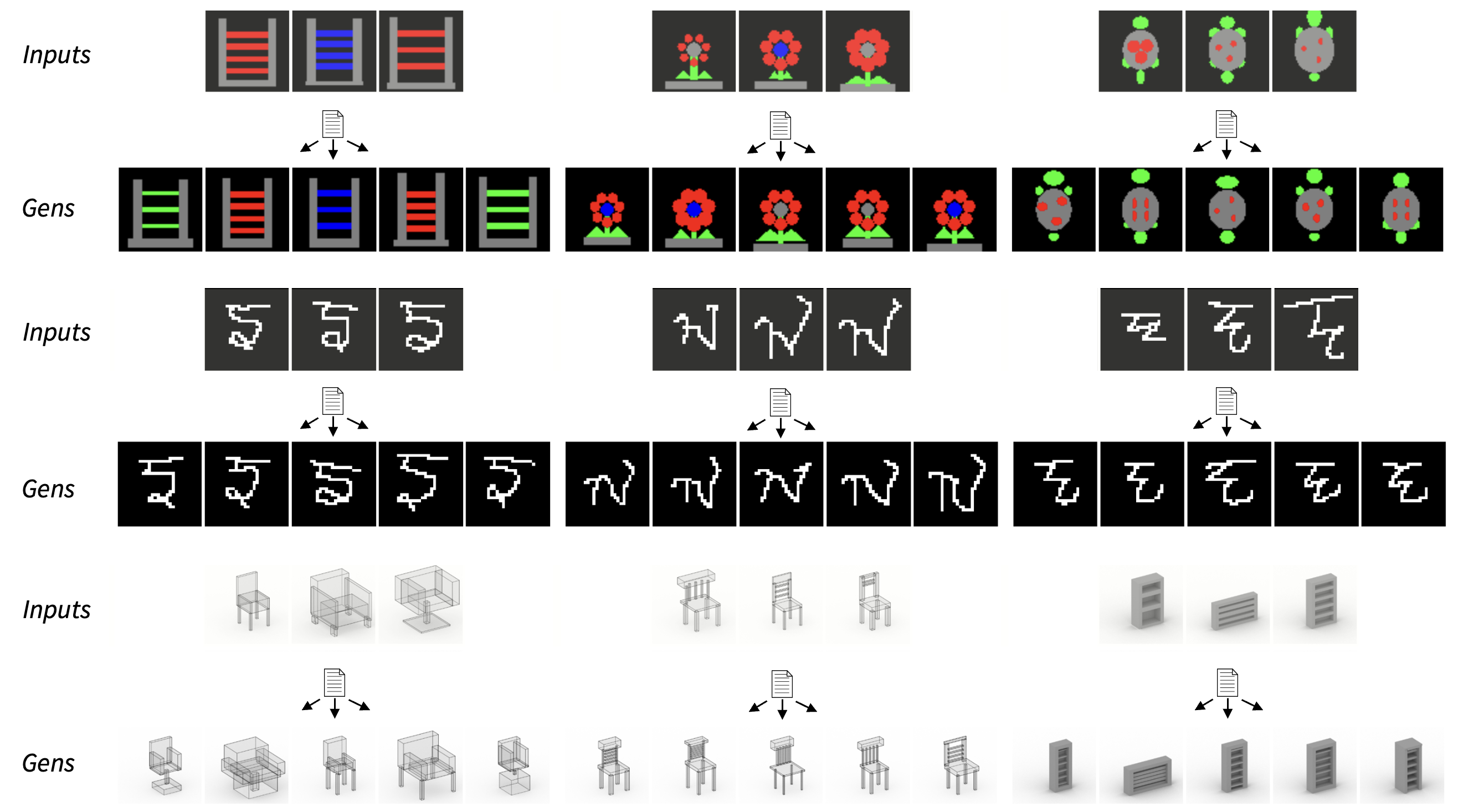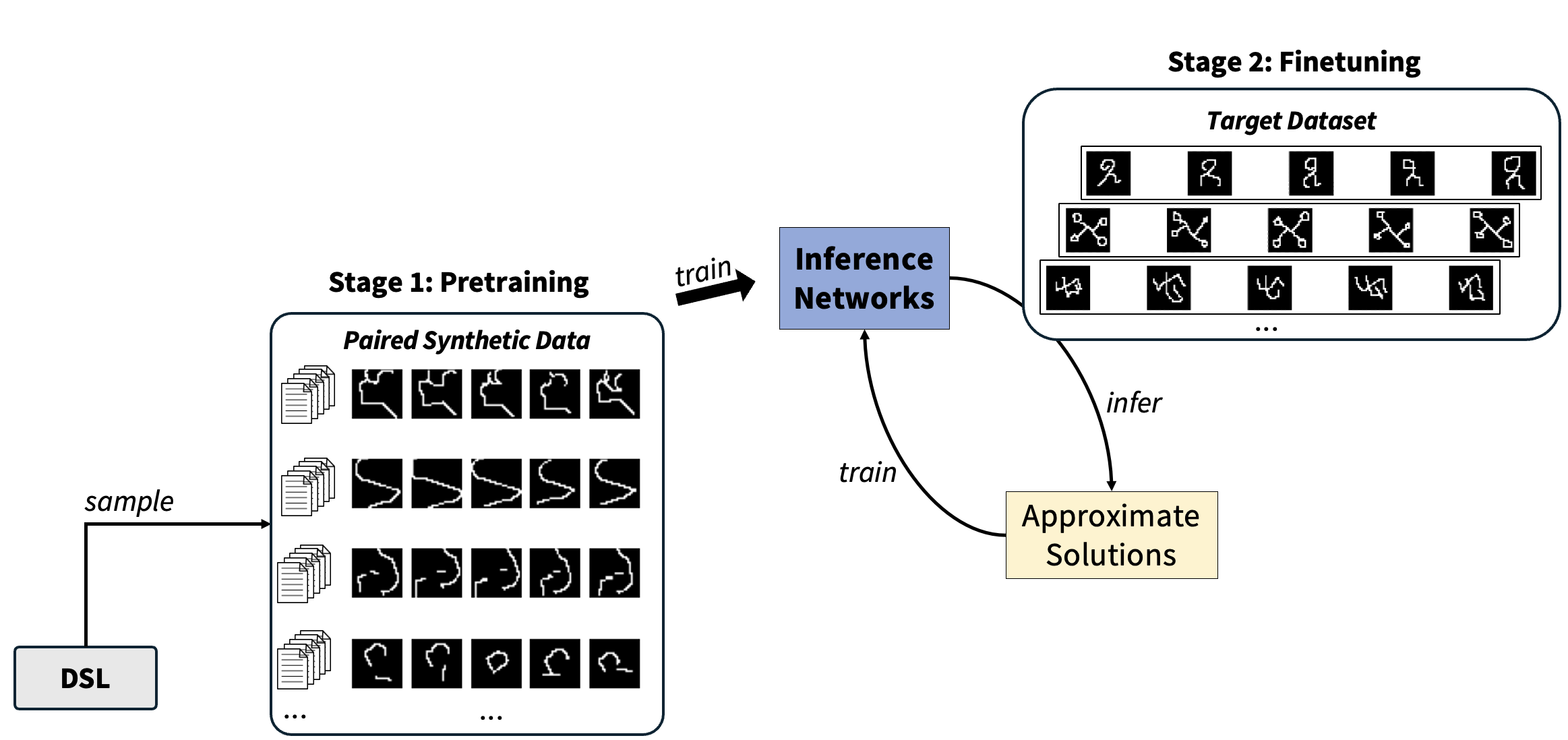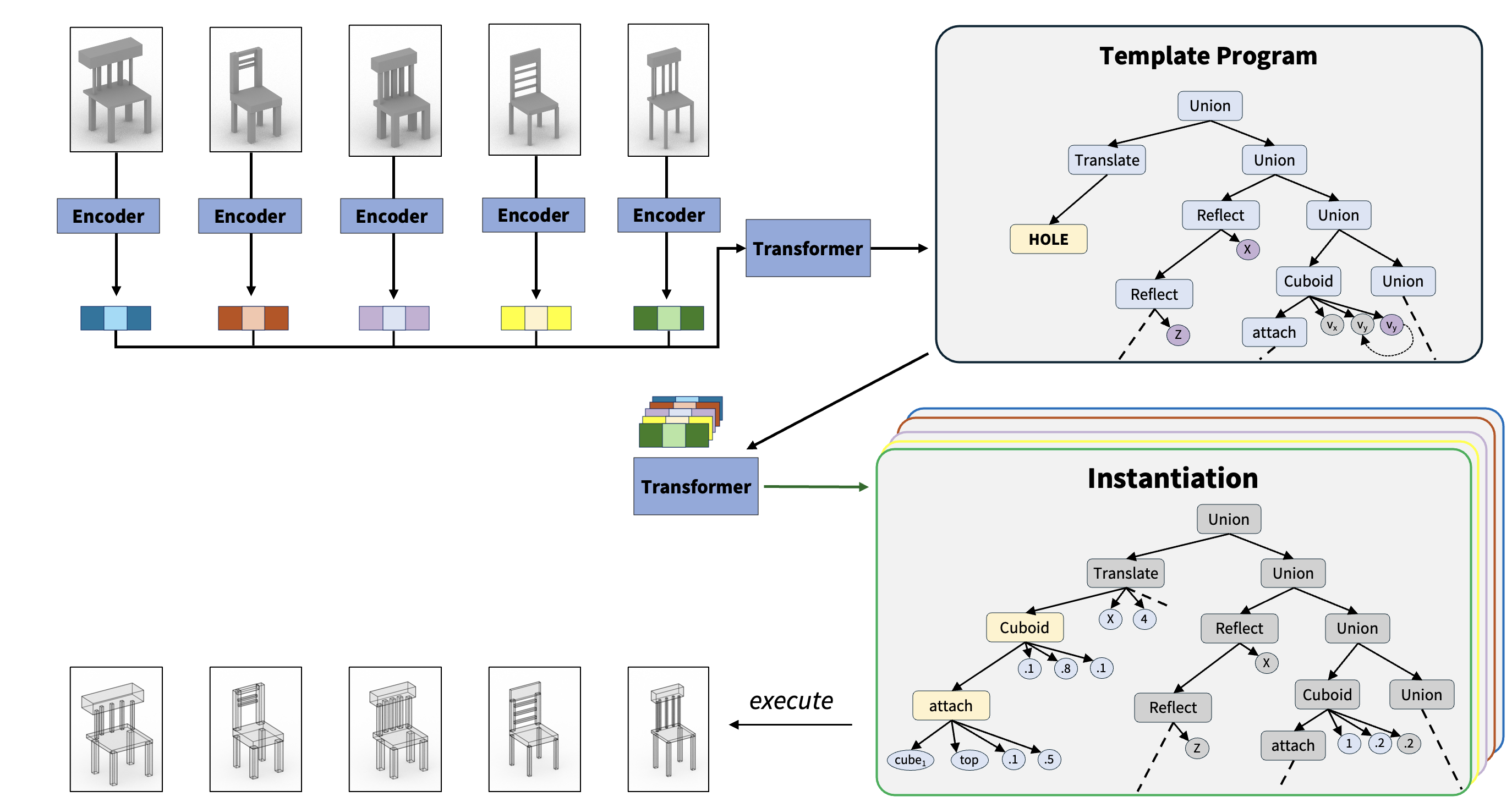
| R. Kenny Jones1 Siddhartha Chaudhuri2 Daniel Ritchie1 |
| 1Brown University 2Adobe Research |
@inproceedings{jones2024TemplatePrograms,
title= {Learning to Infer Generative Template Programs for Visual Concepts},
author= {Jones, R. Kenny and Chaudhuri, Siddhartha and Ritchie, Daniel},
booktitle = {International Conference on Machine Learning (ICML)},
year= {2024}
}